ObjectReact agent navigates using a learnt controller conditioned on a WayObject Costmap representation, which breaks down visible objects by distance to the goal. Object distances are estimated using an object-level relative 3D scene graph.
Abstract
Visual navigation using only a single camera and a topological map has
recently become an appealing alternative to methods that require
additional sensors and 3D maps. This is typically achieved through an
image-relative approach to estimating control from a given pair
of current observation and subgoal image. However, image-level
representations of the world have limitations because images are strictly
tied to the agent's pose and embodiment. In contrast, objects, being a
property of the map, offer an embodiment- and trajectory-invariant world
representation. In this work, we present a new paradigm of learning
object-relative control that exhibits several desirable
characteristics:
a) New routes can be traversed without strictly
requiring to imitate prior experience,
b) The control prediction
problem can be decoupled from solving the image matching problem,
and
c) High invariance can be achieved in cross-embodiment
deployment for variations across both training-testing and
mapping-execution settings.
We propose a topometric map representation
in the form of a relative 3D scene graph, which is used to
obtain more informative object-level global path planning costs. We train
a local controller, dubbed ObjectReact, conditioned directly on
a high-level "WayObject Costmap"
representation that eliminates the
need for an explicit RGB input. We demonstrate the advantages of learning
object-relative control over its
image-relative counterpart across sensor height variations and multiple
navigation tasks that challenge the underlying spatial understanding
capability, e.g., navigating a map trajectory in the reverse direction.
We further show that our sim-only policy is able to generalize well to
real-world indoor environments.
ObjectReact Pipeline
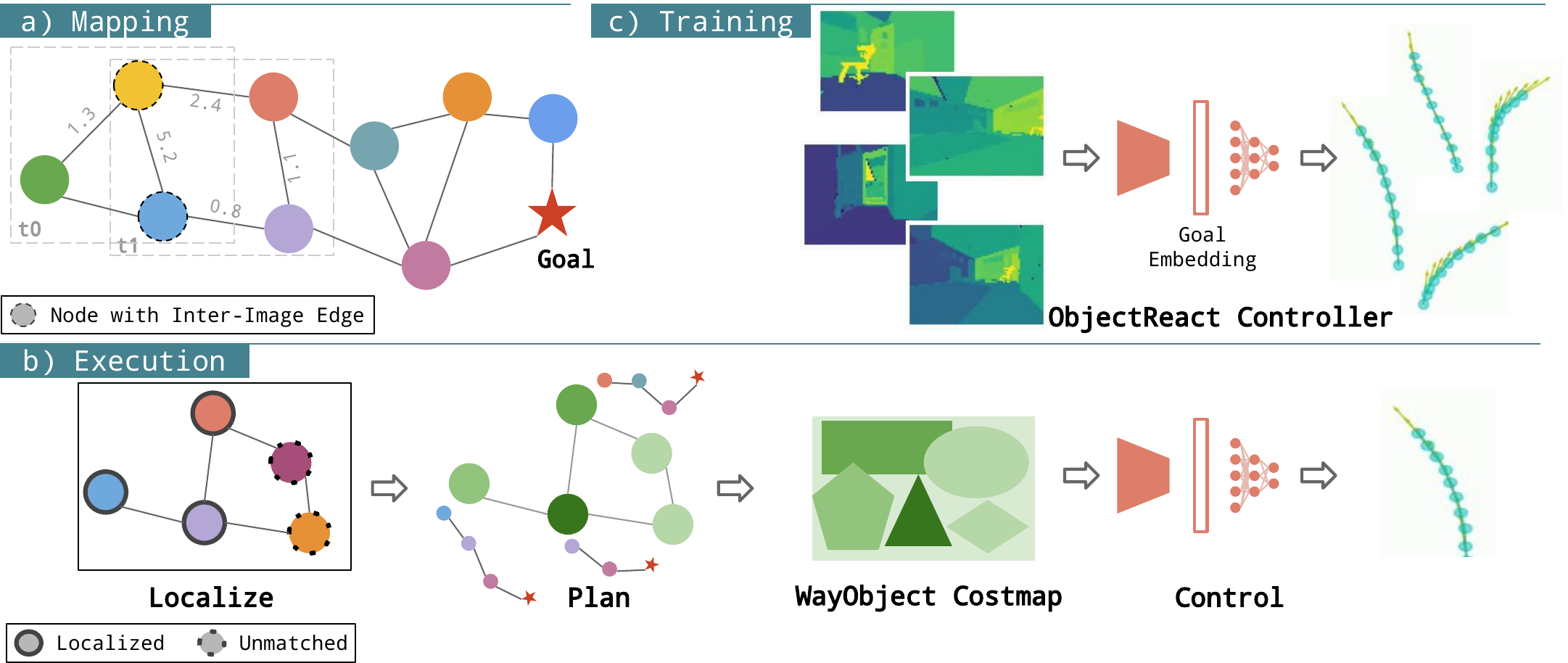
a) Mapping: We construct a topometric map as a relative 3D scene graph, where image segments are used as object nodes, which are connected intra-image using 3D Euclidean distances and inter-image using object association. b) Execution: Given the map, we localize each of the query objects and compute its path to the goal node; we assign these path lengths to the object's segmentation mask, forming a “WayObject Costmap” for control prediction. c) Training: We train a model to learn an “ObjectReact” controller that predicts trajectory rollouts from WayObject Costmaps.
Cross-Embodiment Deployment
Phone Video: Used to generate the object-level map.
a) Cross-embodiment deployment between mapping and execution
b) Avoids new obstacles not present during mapping
c) Low-light adaptation
d) Alt goal tasks
One map video (taken using a phone camera), can be used for deployment a) on a quadruped robot with a different camera, b) with new obstacles, c) under reduced lighting conditions, and d) navigating to an alternative goal that was on the periphery of the mapping run (deployment shown at 8x speed).
Shortcut Task
Long mapping video: The mapping run takes a longer
path to the goal (using a phone camera).
Deployment: The robot takes a direct path
to the cardboard cutout goal.
ObjectReact can take shortcuts that were not demonstrated during the mapping run (deployment shown at 8x speed).
New Tasks
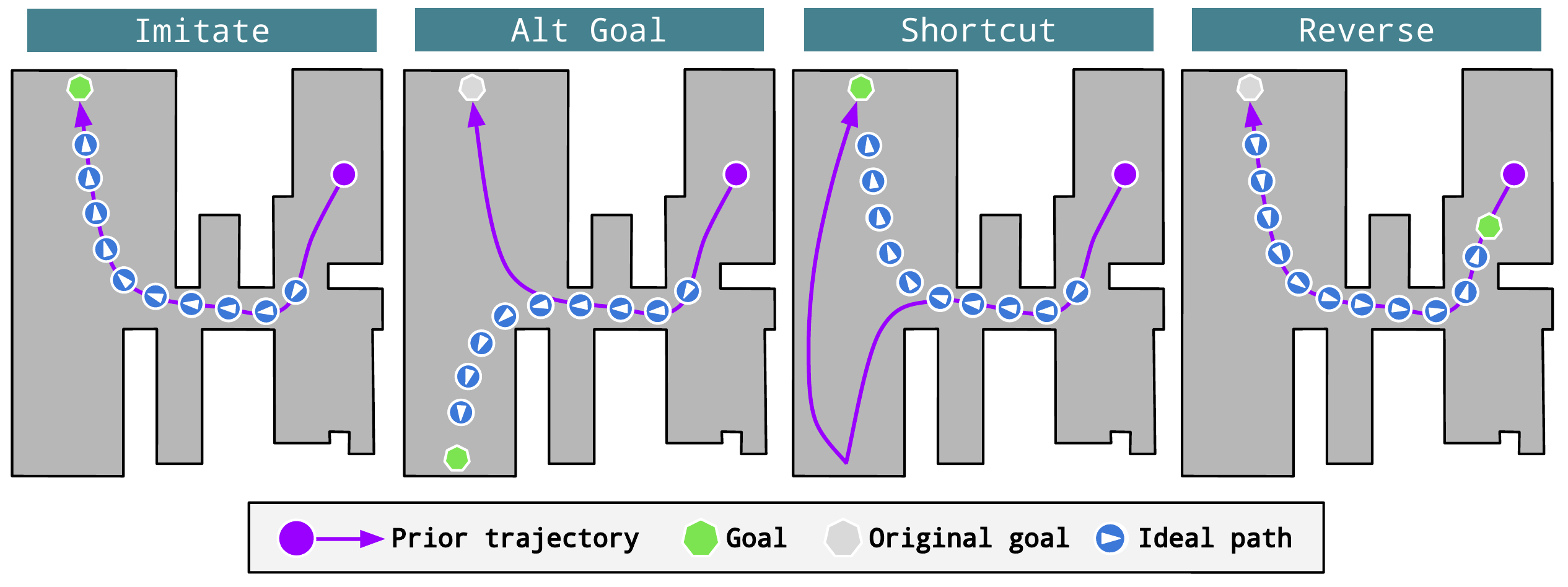
Each column shows a topdown view with the prior experience (map) trajectory displayed as a purple path from the purple circle (start) to green point (goal). Imitate is akin to teach-and-repeat. In Alt-Goal, the goal object is previously seen but is unvisited. In Shortcut, the prior mapping trajectory is made longer, and agents are able to take a shortcut to achieve the goal using a shorter path. In Reverse, the agent must travel in the opposite direction to the prior mapping run.
Results

ObjectReact (Object Relative) performs similarly for the simpler Imitate task, but significantly outperforms its image relative counterpart in all other cases.
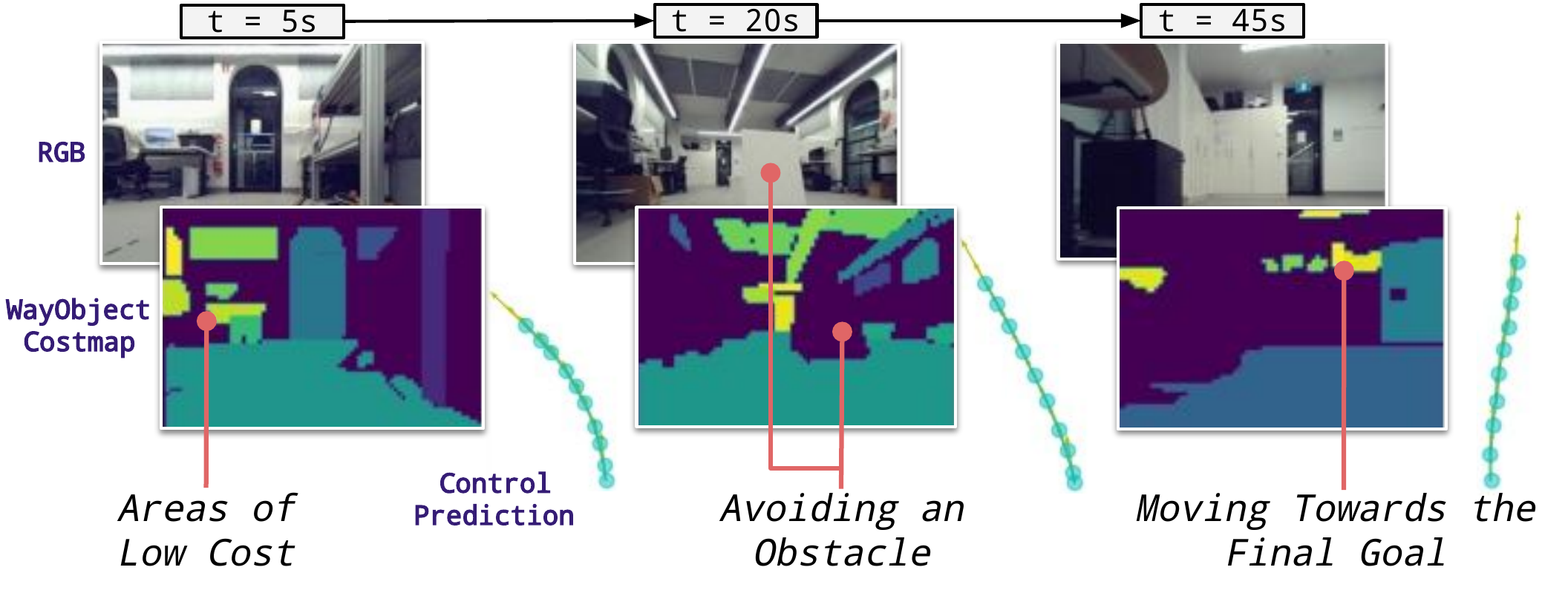
Rollout examples. ObjectReact prefers to navigate towards areas of lower estimated cost/closer proximity to the goal (green-yellow), and can avoid obstacles not present during the mapping run.
Other Deployment Videos
Mapping run: Map video was taken during the daytime with a phone camera.
Deployment: ObjectReact policy is deployed in the evening.
Adapting to new lighting conditions. A map generated during the day can be used at night (deployment shown at 9x speed).
Goal: Paper bag.
Goal: Cardboard cutout.
Goal: Wooden board.
Goal: Computer.
Same camera between mapping and execution. The map uses a prior run on the Unitree Go1 quadruped robot (deployment shown at 8x speed).
Obstacles: Training demonstrations closely corner around obstacles, leaving little margin for error during deployment.
Matching large objects: Large objects can have high connectivity in the topometric map, leading to WayObject Costmaps that have large regions of similar cost.
Imitate (sim): Some areas in the simulator may appear to be navigable when they are blocked by an obstacle.
Reverse (sim): The reverse task requires navigating from perspectives that are very different from those seen during the mapping run.
Shortcut (sim): Diverging from mapping run and facing away from the goal can lead to uninformative relative costs.
Alt Goal (sim): The policy does not leave a large margin around obstacles, which can lead to collisions during deployment.
Failure cases. Due to the challenging sim-to-real and cross-embodiment conditions and inference-based perception pipeline, ObjectReact has several common failure modes (real-world deployment shown at 8x speed, simulation at realtime speed).
Goal:Wooden board.
Goal: Cardboard cutout.
Goal: Computer.
Obstacles. ObjectReact can adapt to new or relocated objects that between mapping and execution (deployment shown at 8x speed).
BibTeX
@inproceedings{garg2025objectreact,
title={ObjectReact: Learning Object-Relative Control for Visual Navigation},
author={Garg, Sourav and Craggs, Dustin and Bhat, Vineeth and Mares, Lachlan and Podgorski, Stefan and Krishna, Madhava and Dayoub, Feras and Reid, Ian},
booktitle={Conference on Robot Learning},
year={2025},
organization={PMLR}
}